The Open Reaction Database (ORD): Revolutionizing Chemical Reaction Design with AI
Regardless of where you stand in relation to the adoption of AI (or not), the increasing role of digital technology on our lives is a hot topic and the subject of much debate. And it’s use within the field of chemistry is no exception. The use of digital tools such as AI and ML within chemistry, either through target identification, drug design or data analysis is increasingly common, as has been outlined in our recent blog article.
However, while much work has been completed towards target identification, drug design and interpretation of data in statistical terms, the development of reliable tools to support reaction design, i.e. synthesis of drug-like molecules rather than just suggesting structures, has received much less attention. And this is probably because it’s much more difficult, with a lot of reaction design and synthetic route development relying upon a chemist’s prior experience and intuition. ls.
Why is chemical reaction data difficult for AI to use?
Imagine trying to teach a machine to bake a cake, but all your recipes are written differently, some are incomplete, and many only tell you what worked, not what failed. This is the challenge faced by chemists that want to leverage AI for reaction design.
Chemical reaction data, often scattered across journal articles, patents, and even electronic laboratory notebooks, are currently stored in various, often unstructured, formats. This presents a significant barrier to downstream applications, including the training of machine-learning models.
For example, while the US Patent Office (USPTO) database offers openly accessible data, users must pay to access other large datasets, like Reaxys and SciFinder. Moreover, journal articles, despite containing a wealth of potentially useful information, often present data in formats that computers cannot easily read.
Even published procedures aren’t optimal for AI and ML because they tend to lack details obvious to a chemist but crucial for an algorithm. Plus scientists rarely report failed reactions, which are essential for machine-learning models to understand what doesn't work.
Collectively, these factors are hindering the successful implementation of AI and ML in reaction design.
What is the Open Reaction Database (ORD) and how does it solve data problems?
In a recent podcast, ConsultaChem spoke with Dr Ben Deadman, a specialist consultant in digital chemistry who works with an organisation called The Open Reaction Database (ORD). Addressing critical challenges in chemical reaction data, the ORD provides a progressive solution to the challenges around implementing AI and ML in reaction design.
The ORD is an open-access schema and infrastructure, hosted on GitHub, specifically designed for structuring and sharing organic reaction data through a centralized data repository. Its overarching goal is to “support machine learning and related efforts in reaction prediction, chemical synthesis planning, and experiment design”. This goal is achieved through consistent data representation and infrastructure, which is crucial for overall success.
The core principle behind ORD is data standardization, ensuring useful information like reagents, temperature, pressure, types of glassware used, and data formatting are all machine-readable. This structured approach allows algorithms to interrogate the data effectively and generate usable outcomes.
How has the Open Reaction Database grown and what data does it contain?
The idea behind the ORD is catching on: since their initial meeting in June 2019, the database has grown to over 2 million reactions, with relevant contributions from both industrial and academic users, as well as published and unpublished work. This demonstrates the increasing recognition of the need for standardized, open chemical reaction data.
The quality of data input is crucial for the success of this project, particularly in relation to the algorithm’s interrogation of the data and subsequent generation of useable outcomes. The ORD schema contains both structured and unstructured (free text) fields that are used to document chemical reactions; the most important information is captured in a structured format, and additional details are provided in an unstructured format. Each record entered should be a verbatim account of what happened in the laboratory, rather than a standardised protocol. The schema is divided into nine sections: reaction identifiers, inputs, setup, conditions, notes, observations, workups, outcomes (products and analytics), and provenance, Figure 1.

Figure 1: Overview of the Open Reaction Database schema. Taken from J. Am. Chem. Soc. 2021, 143, 45, 18820–18826.
Figure 1: Overview of the Open Reaction Database schema. Taken from J. Am. Chem. Soc. 2021, 143, 45, 18820–18826.Each of the nine sections has child objects, where further data can be added, Figure 2. The fields of each schema object are structured to constrain their types or values, such as only allowing positive numeric values for amounts or limiting the units to a set of predefined constants.
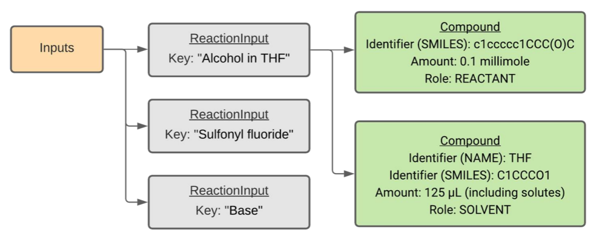
Figure 2: Example schema inputs. The “Alcohol in THF” input is further expanded to show its solute and solvent components. For examples of the set-up and conditions and the outcomes schema, see J. Am. Chem. Soc. 2021, 143, 45, 18820–18826.
Figure 2: Example schema inputs. The “Alcohol in THF” input is further expanded to show its solute and solvent components. For examples of the set-up and conditions and the outcomes schema, see J. Am. Chem. Soc. 2021, 143, 45, 18820–18826.How can I access and use the Open Reaction Database for data mining?
The database can be browsed through the web editor on the ORD website. Within the ORD iterative editor, reaction inputs, reaction conditions, and work-up can all be accessed, along with defined reaction outcomes. For more in-depth data mining and ML work, users are advised to use the GitHub site. This allows access to the whole ORD or to individual datasets, as appropriate. For more information on how to mine the database effectively, ORD have compiled a short blog.
What are the FAIR principles and why are they important to ORD?
Any one person can contribute to the database, with submissions primarily handled through GitHub. The ORD is, as its name suggests, an open database, therefore all data and code associated is publicly available under commonly-used licenses that protect open access – the FAIR principles. This is different open-access journals, where publicly funded research is available for all to see but data in the Supporting Information, usually as a PDF, leaves significant barriers to researchers finding it and using it within in ML algorithms effectively.
Crucially, the database is purposely designed to avoid the control or influence of a single institution. This safeguards the core data and functionality, ensuring it remains unaffected should any contributor choose to cease their involvement in the initiative. This decentralized approach builds trust and ensures the long-term viability of ORD as a vital resource.
What's next for the Open Reaction Database?
The Open Reaction Database is continuously evolving and developing to meet the needs of the chemistry community. This encompasses both contributors inputting the information, and researchers utilizing and progressing the information.
At the time of writing, within ORD there are 2.3 million reactions and 130,000 curated submissions, mainly from Daniel Lowe’s US Patent Office (USPTO) database.
Looking ahead, exciting developments are on the horizon:
The ORD HTE Center Grant has opened a call for proposals (deadline, Friday, July 18, 2025), and will fund the development of 6 large, open-access reaction datasets for the community.
A new online interface is currently undergoing beta-testing, with public release expected in June 2025.
This platform needs more people to become involved. If you have data that can be made open access, you can help! Contact ORD directly: help@open-reaction-database.org.
By contributing to - and championing - the Open Reaction Database, chemists can overcome the hurdles of unstructured data and limited access. The benefit being that the entire community pulls together to pave the way for more efficient and innovative reaction design through the power of AI and machine learning.